Analysis Method for Custom Encoding
In diary entry "Deobfuscating a VBS Script With Custom Encoding", I decoded a reader submitted VBS script with custom encoding of the payload.
Here is the command to extract the encoded payload:

In my previous diary entry, I figured out how to decode this payload by reversing the VBS decoding routine.
In this diary entry, I will show you how to figure out which encoding method that was used through statistical analysis. This can be useful if you don't have access to the decoding routine.
First, I pipe the encoded string into my byte-stats.py tool. This tool calculates many statistical values for the data it receives as input (it handles the input as a stream of bytes):
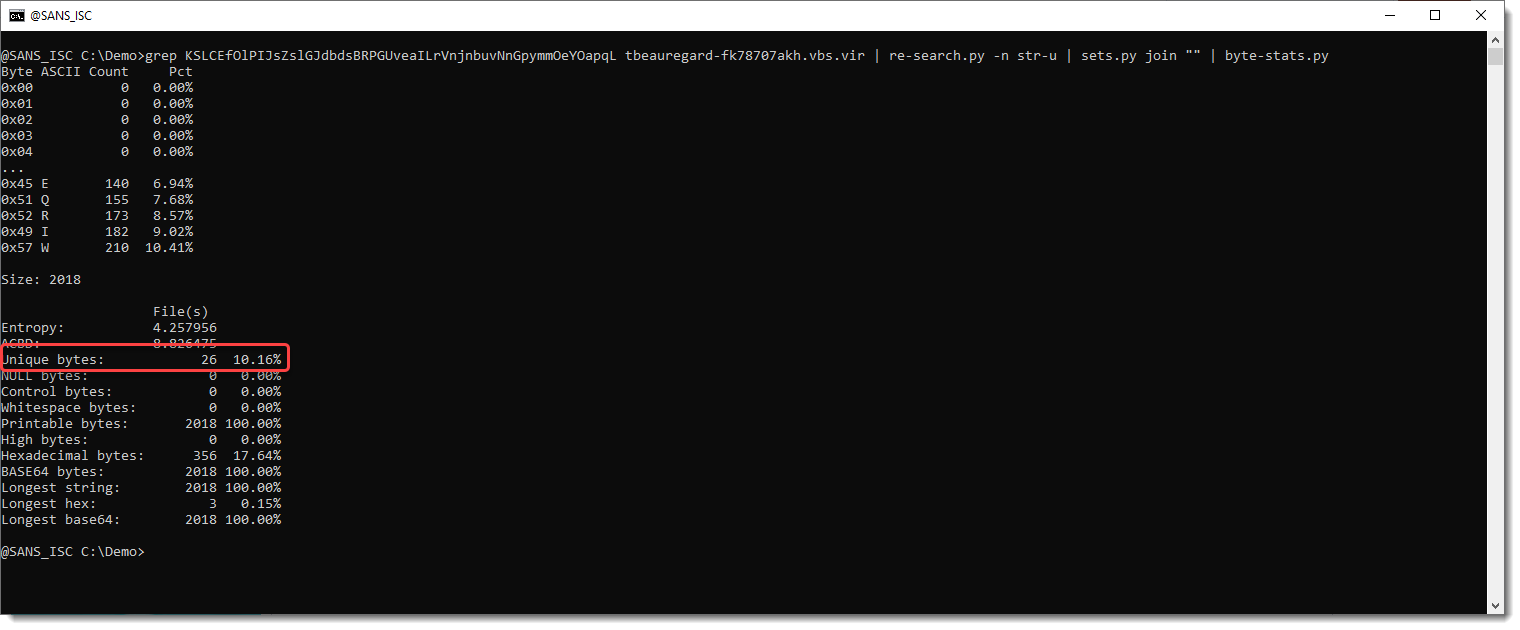
I can see that there are only 26 unique values. All printable, and the most prevalent are uppercase letters. With option -r, I can generate a range of values:
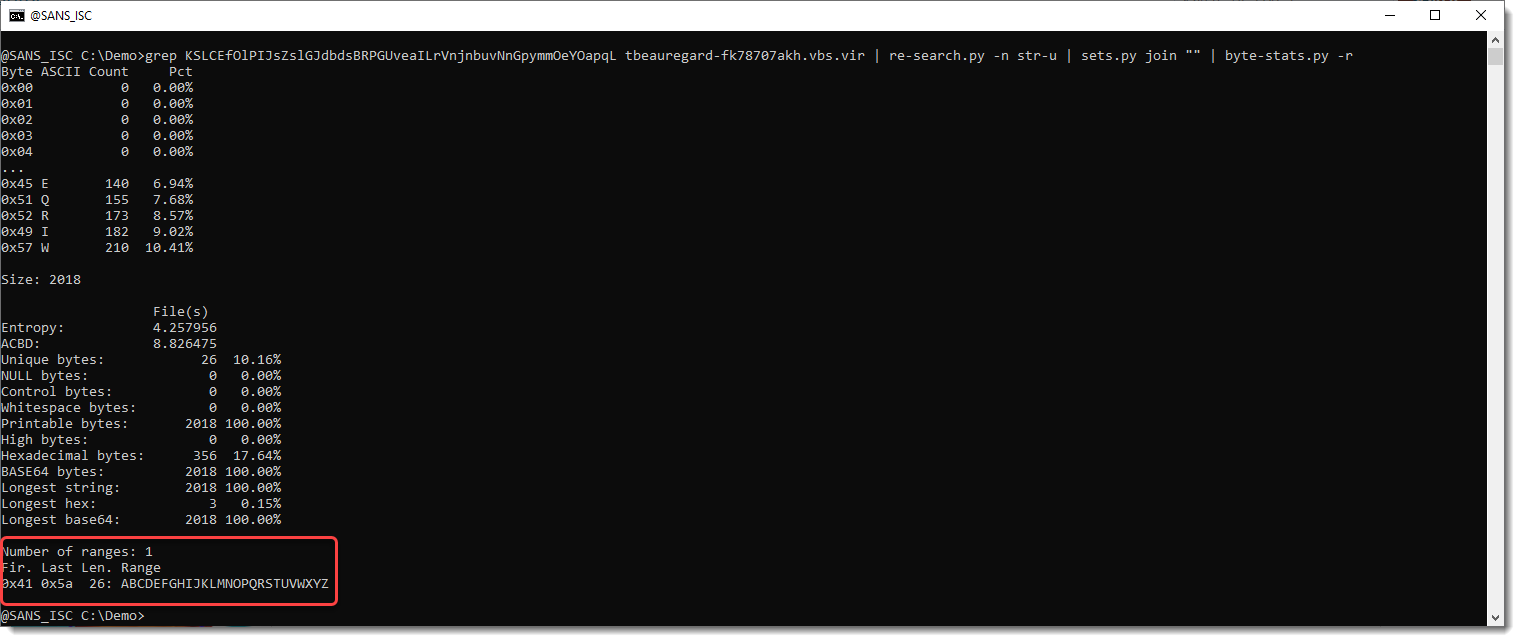
So the encoded payload consists of all the uppercase letters, and nothing else.
26 values is not enough to encode a payload like a VBS script (unless the script is very short).
As 26 is not enough, the encoding must use more than one letter to encode a character.
I will start with a simple hypothesis: 2 letters are used to encode a single character. 2 letters gives use 26 * 26 = 676 possibilities, that's more than enough to encode each possible byte value (256 distinct values). I will call such a pair of 2 letters a token.
My tool python-per-line.py can be used to split the payload into tokens of 2 letters. This is done with Python function Chunkify, one of the functions defined by python-per-line.py.
I use it like this (headtail.py is used to limit the output to a single screenshot):
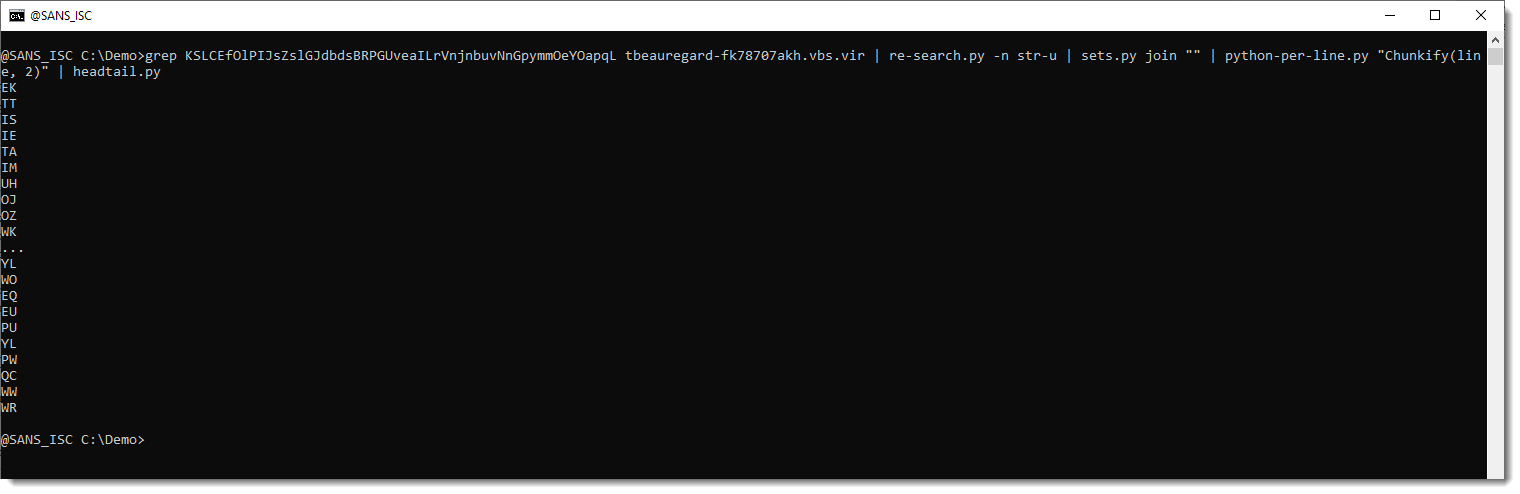
So python-per-line.py applies the given Python expression to each line of input it receives. Variable line contains a line of the text input file, Python expression Chunkify(line, 2) splits the line into a list of strings that are 2 characters long. When a Python expression returns a list in stead of a string, python-per-line.py will print each item of the list on a separate line.
After tokenizing the payload into 2 characters-long tokens, I want to calculate the frequency of each token. This can be done with my tool count.py. count.py takes text files as input, and calculates the frequency of each line (how many times each line appears). Option -t (totals) produces some extra statistics:
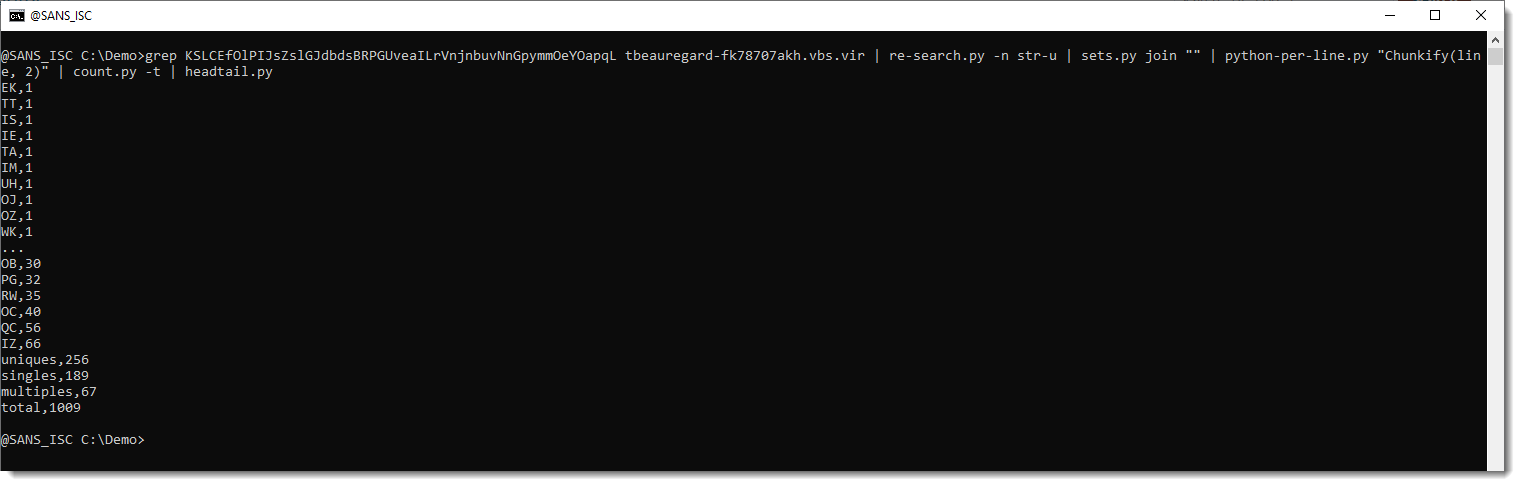
Since each token appears on a single line, the output of count.py gives us statistics for the tokens.
unique,256: this means that there are 256 unique tokens. That's already very useful information to help with the decoding, because 256 is exactly the number of unique values a single byte can have. Thus it is indeed possible in this case, that 2 letters are used to encode a single byte.
singles,189: this means that out of the 256 unique tokens, there are 189 unique tokens that appear just once.
multiples,67: this means that out of the 256 unique tokens, there are 67 unique tokens that appear more than once.
total,1009: there are 1009 tokens in total.
And I can also see that token EK appears only once and that token IZ is the most frequent, it appears 66 times.
To translate tokens into byte values, we need a translation table. For example, token AA could represent byte value 0x00, token AB could represent byte value 0x01, and so on ...
But that's not the case here, since token AA does not appear in the payload.
The translation table can be stored inside the decoding routine or it can be stored inside the payload itself. Since the payload is encoding a VBS script, it is very unlikely that all possible byte values are present in the unencoded script (for example, most control characters will not be used). Thus if the encoded payload would not contain a translation table, we would no see all 256 possible tokens. Since we do see all 256 possible tokens in this payload, I'm going to work with the hypothesis that the payload contains a translation table.
First test I will make, is check if the translation table is stored first in the encoded payload. So I select the first 256 tokens ([:256]) and calculate statistics:
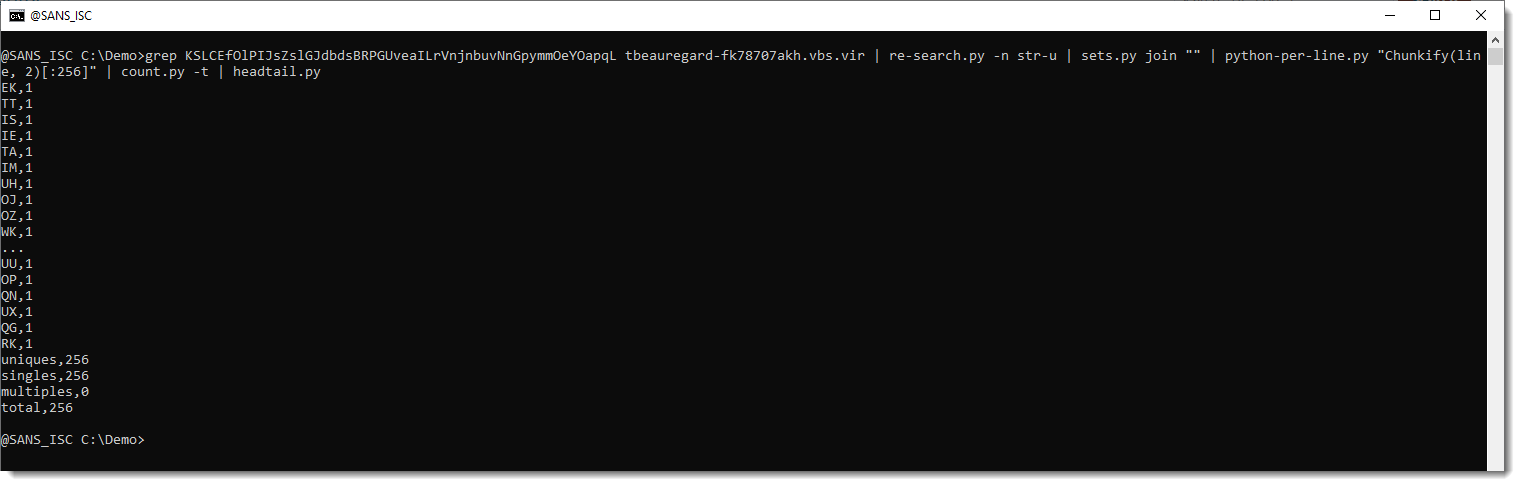
That's more good news: the first 256 tokens only appear once. So this could be a translation table. Let's check the remaining tokens (e.g., the tokens that follow the first 256 tokens):
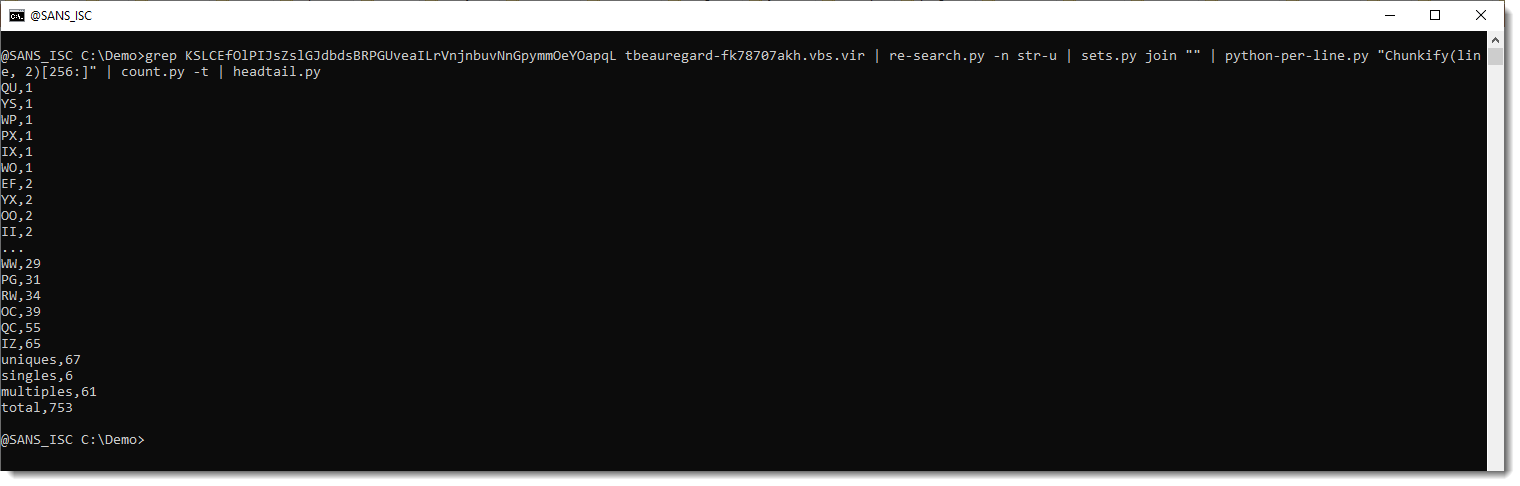
And here we only have 67 unique tokens: so it's likely that the first 256 tokens define the translation table, and the remainder is the encoded payload.
The tokens that appear the most freqently are: IZ, GC, OC.
Let's see how we can translate these.
So this is our translation table:
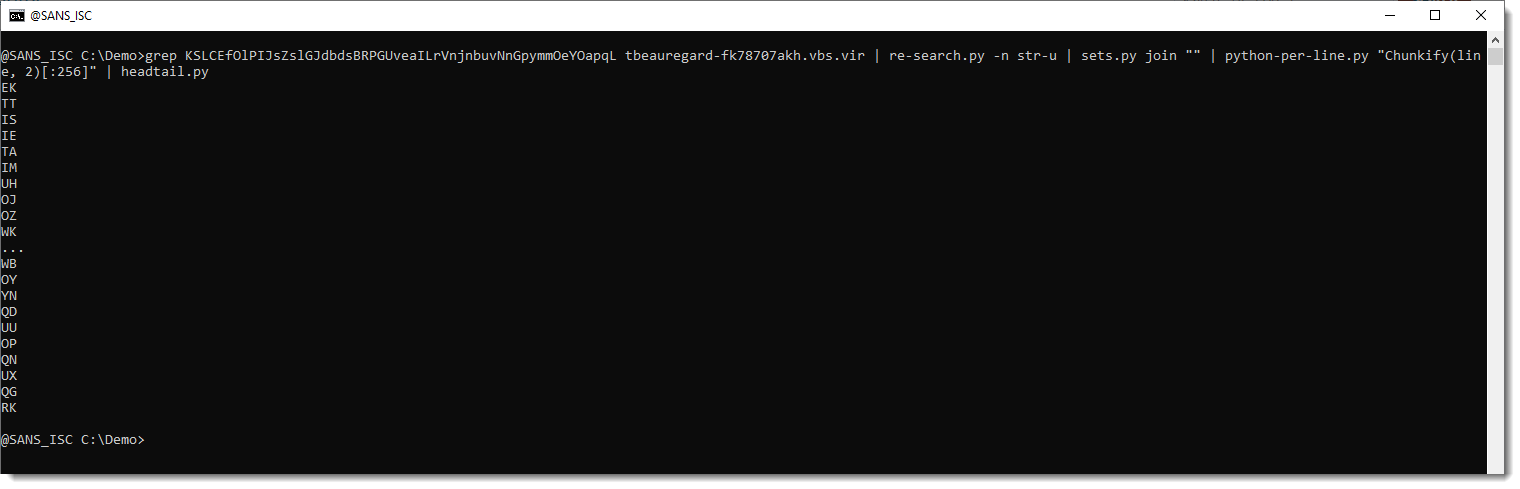
Token EK is the first in the translation table, and RK is the last one. Again, I'll work with a simple hypothesis: that the list of tokens in the translation table is just sequential: that EK represents byte value 0x00, TT value 0x01, and finaly, that RK represents byte value 0xFF (255).
I will use Python's enumerate function to prefix each token with its index:
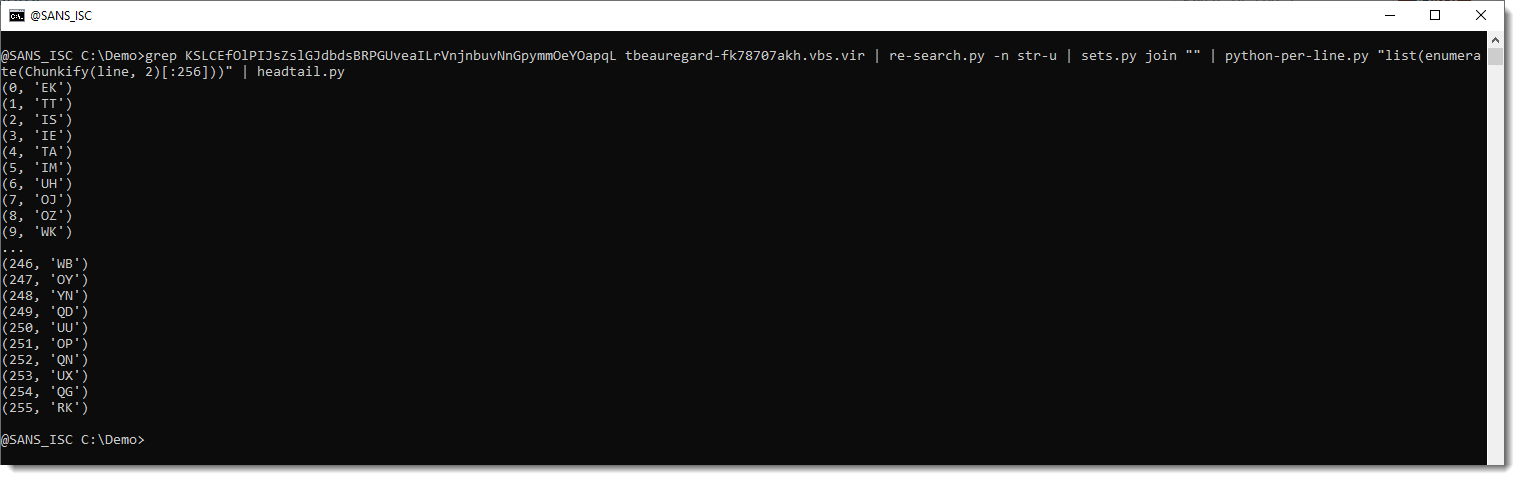
And one more step, I will also add the ANSI representation (chr(index)):
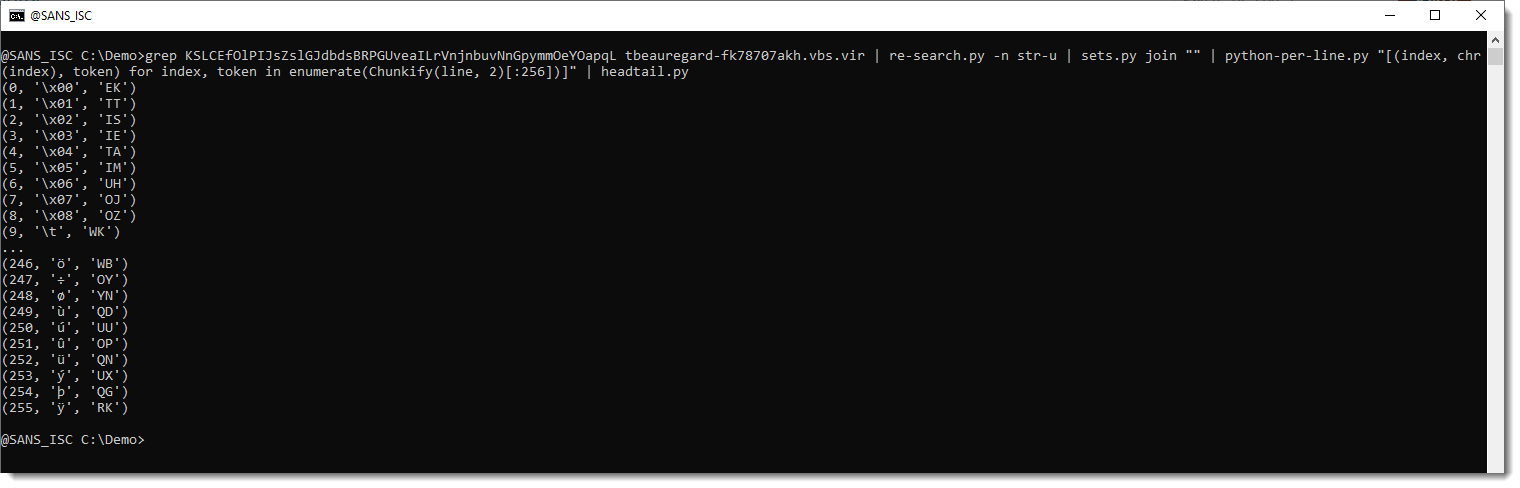
So with my hypothesis, for example, token WK represents byte value 0x09 and that's the TAB character.
Let's grep for the most prevalent tokens (IZ, GC, OC)

So the most prevalent tokens represent letter e, the space character, and letter r. Which is more or less in line with the prevalence of characters in English texts (and by extension, scripts).
What rests me to do, is write a decoding routine, and that is what I did in my previous diary entry.
.png)
To summarize: this encoding method was rather simple, as it confirmed simple hypotheses. A token is a pair of 2 uppercase letters, each token represents a byte value, the first 256 tokens of the encoded payload define the translation table, the translation table is sequential, the remainder of the encoded payload is the encoded script.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments