Deobfuscating Scripts: When Encodings Help
I found this sample on MalwareBazaar, tagged as unknown.
Taking a look with my tool file-magic.py:
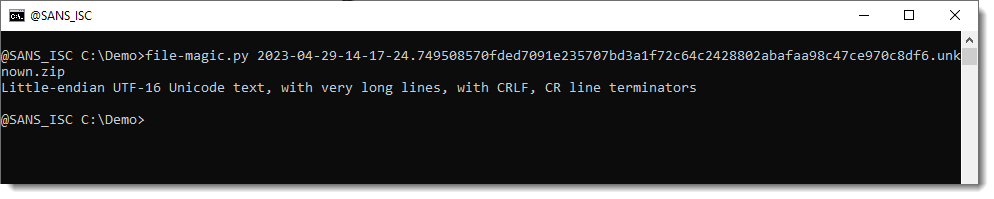
It's UTF16 LE text. This is confirmed when taking a look at the malware file inside the ZIP container with zipdump.py:
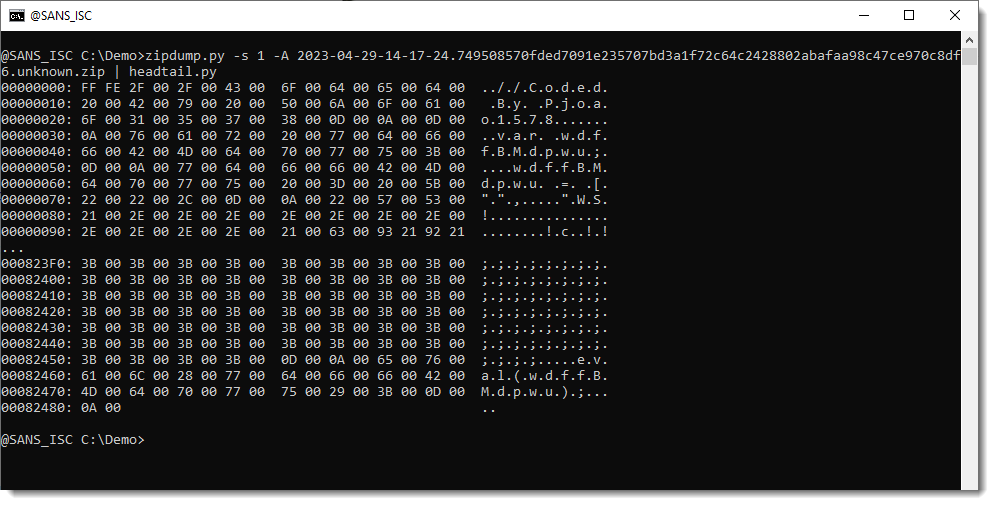
Notice the FFFE BOM.
zipdump.py can convert utf16 text to utf8 text with option translate (-t utf16):
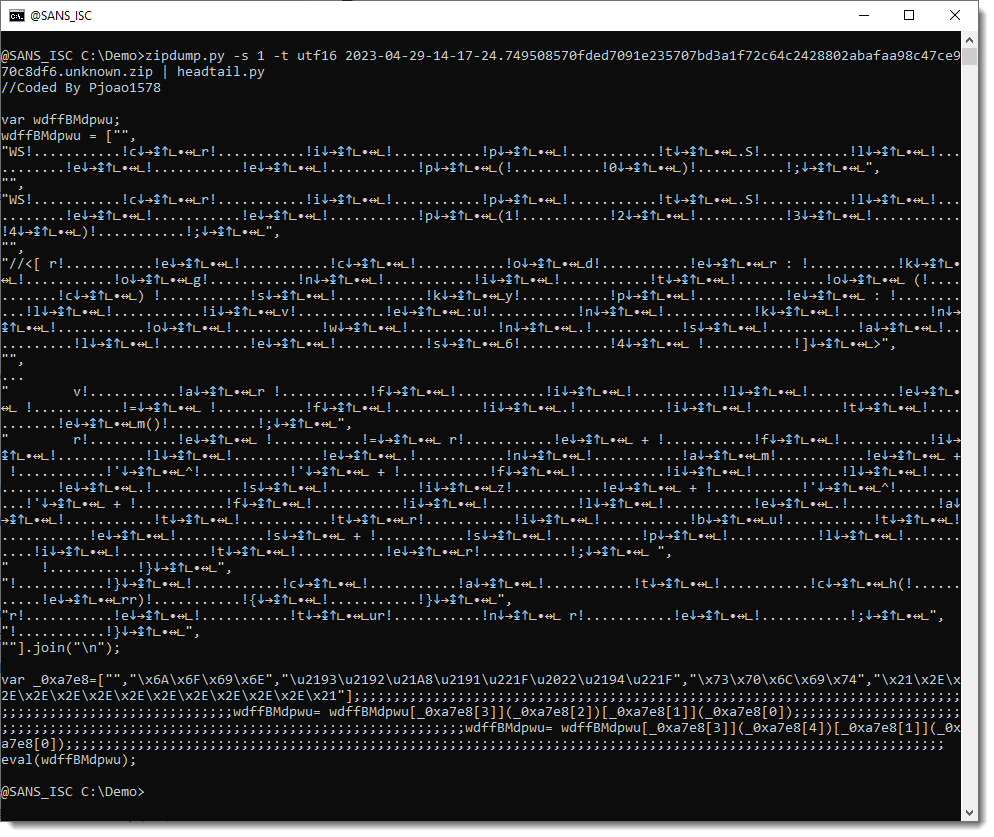
A search for the name in the first comment gives me already an indication of what this might be.
Taking a look at the encoded strings at the end of the file (grep var) with base64dump.py gives me this:
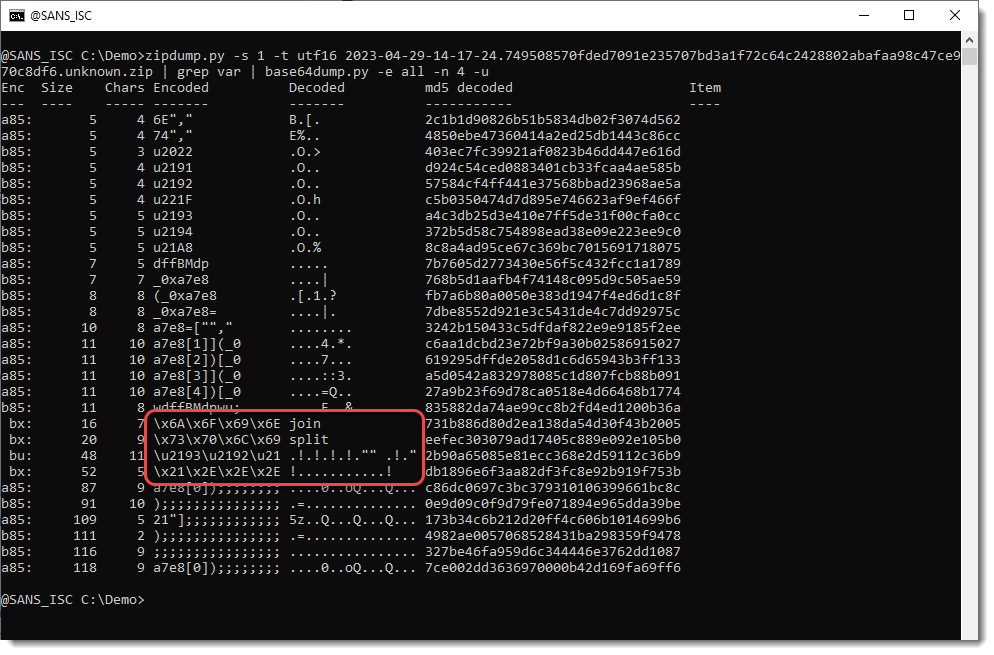
split and join: the strings are split according to a given separator, and then joined together again. The result is that the "separator" has been removed.
The "separators" are the 2 last strings in the red box above.
The \u notation (like \u2193) is a unicode code point notation supported in JavaScript: that string representents different arrow symbols, that are inserted into the script for obfuscation. I could search and replace for these arrows, but there's an easier method. Since these are non-ANSI characters, I can just convert the utf16 text to latin (ANSI), like this (i=utf16 means input is utf16, o=latin means output should be latin).
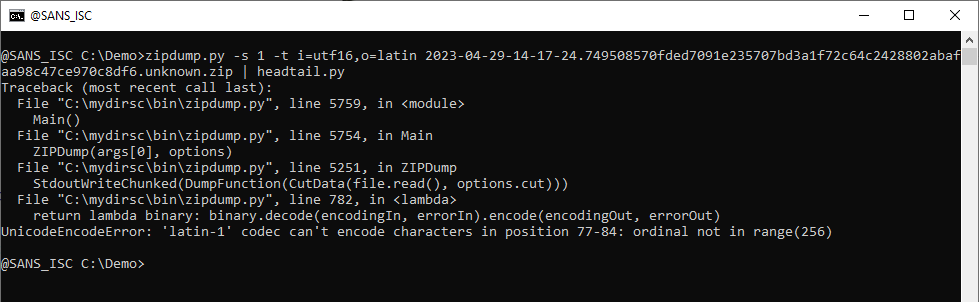
As can be seen, this throws an error, because the latin-1 codec can not handle these arrow characters. The trick is to let the latin-1 codec ignore (drop) these characters: latin:ignore. Like this:
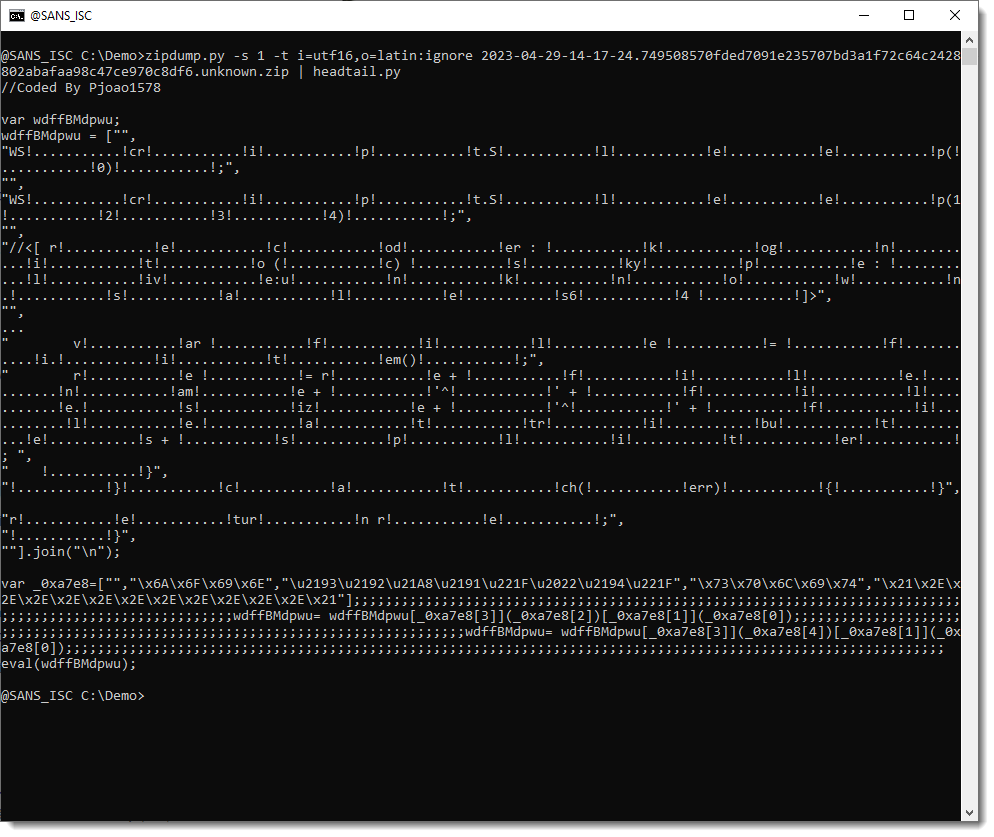
And now all the arrow symbols are gone. I'm left with another obfuscating string that should be removed (!...!). Since this is a ANSI string, I can just remove it with a search and replace with sed:
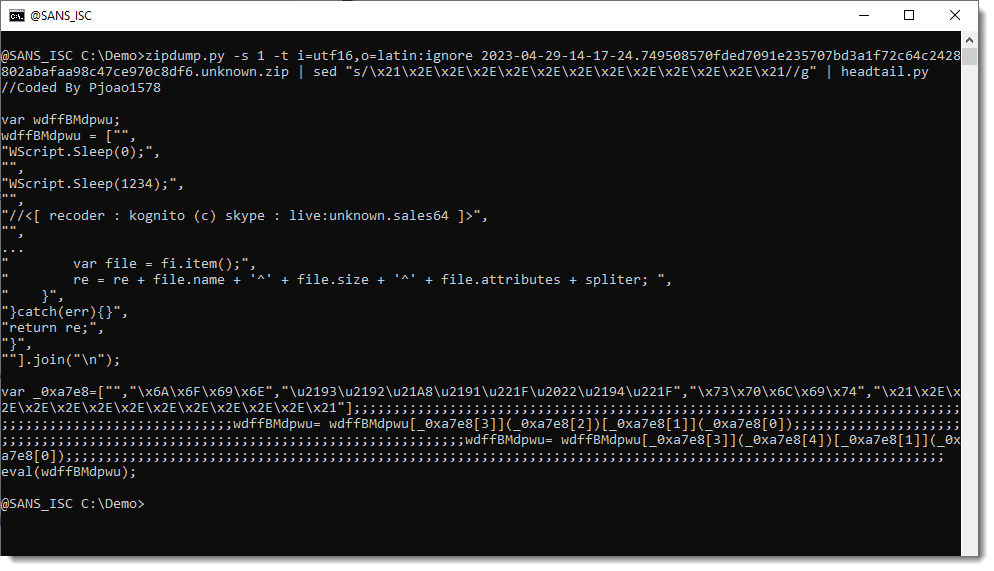
This is a RAT written in JavaScript, probably a variant of hworm/wshrat:
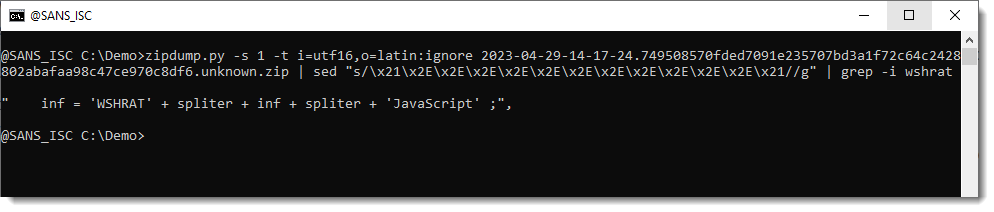
The C2 can be observed in the configuration part of the code:
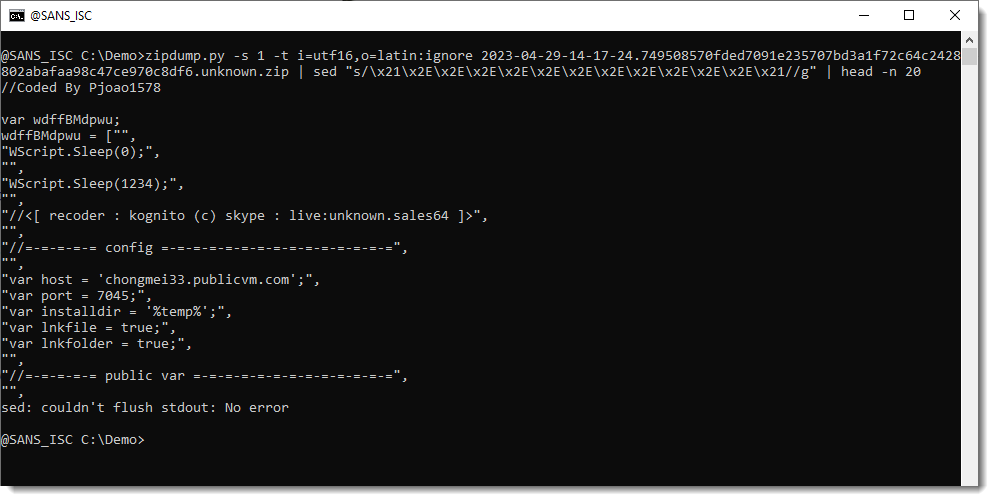
When an ANSI script is obfuscated with non-ANSI characters (in UTF16), one can do a (partial) deobfuscation by converting the script back to ANSI and throw away all non-ANSI characters.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments